Title: キーワードの読みがなで検索できるようにするには
日本語では、同じ言葉を表記する場合でも、漢字、カタカナ、ひらがななど、使われる文字の種類に揺れがあることがあります。例えば、「心」「こころ」「ココロ」など、時と場合によって表記が異なります。
Solr の初期設定では、「心」という文字を含む文章をキーワード「こころ」で検索しても、表記された文字が異なるため、ヒットしません。しかし、以下に述べる方法で、「表記の文字が異なっていても、読みがなが同じならヒットする」という動作に設定できます。
schema.xml の編集
Solr の日本語用設定「traction_ja」の中にある、schema.xml というファイルをテキストエディタで編集します。
メモ: 日本語用設定「traction_ja」については下のリンク先を参照してください。
text_general フィールド
「text_general」で検索して次の箇所を見つけてください。
<fieldType name="text_general" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100">
<analyzer>
<!-- Uncomment this to handle iteration marks: -->
<!-- <charFilter class="solr.JapaneseIterationMarkCharFilterFactory" /> -->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FullNumber.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<analyzer>...</analyzer> スコープの最後に次の 1 行を挿入します。
<filter class="solr.JapaneseReadingFormFilterFactory" useRomaji="false"/>
「text_general」全体は次のようになります。
<fieldType name="text_general" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100">
<analyzer>
<!-- Uncomment this to handle iteration marks: -->
<!-- <charFilter class="solr.JapaneseIterationMarkCharFilterFactory" /> -->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FullNumber.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.JapaneseReadingFormFilterFactory" useRomaji="false"/> <!-- ここに設定を挿入 -->
</analyzer>
</fieldType>
text_search フィールド
「text_general」フィールドのすぐ下に「text_search」フィールドがあります。このフィールドの中には type="index" と type="query" の 2 つの <analyzer> があります。
<fieldType name="text_search" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100" termVectors="true" termPositions="true" termOffsets="true" termPayloads="true">
<analyzer type="index">
<!-- Uncomment this to handle iteration marks: -->
<!-- <charFilter class="solr.JapaneseIterationMarkCharFilterFactory" /> -->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FullNumber.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FullNumber.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/
</analyzer>
</fieldType>
この type="index" と type="query" の両方に上記と同じ 1 行を追加して次のようにします。
<fieldType name="text_search" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100" termVectors="true" termPositions="true" termOffsets="true" termPayloads="true">
<analyzer type="index">
<!-- Uncomment this to handle iteration marks: -->
<!-- <charFilter class="solr.JapaneseIterationMarkCharFilterFactory" /> -->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FullNumber.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.JapaneseReadingFormFilterFactory" useRomaji="false"/> <!-- ここに設定を挿入する -->
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FullNumber.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.JapaneseReadingFormFilterFactory" useRomaji="false"/> <!-- ここに設定を挿入する -->
</analyzer>
</fieldType>
ファイルを上書き保存して、テキストエディタを終了します。
日本語用設定の再インストール
上記で編集した schema.xml を含む「traction_ja」を Solr に再インストールします。
Solr が起動していることを確認し、次のコマンドを実行します。
Windows 環境の場合
zkcli.bat -cmd upconfig -zkhost 127.0.0.1:9983 -confname traction -confdir C:\MyPathSomewhere\com.traction.extsearch.solr\etc\solr\configsets\traction_ja\conf
Linux 環境の場合
sh zkcli.sh -cmd upconfig -zkhost 127.0.0.1:9983 -confname traction -confdir ~/Somewhere/com.traction.extsearch.solr/etc/solr/configsets/traction_ja/conf
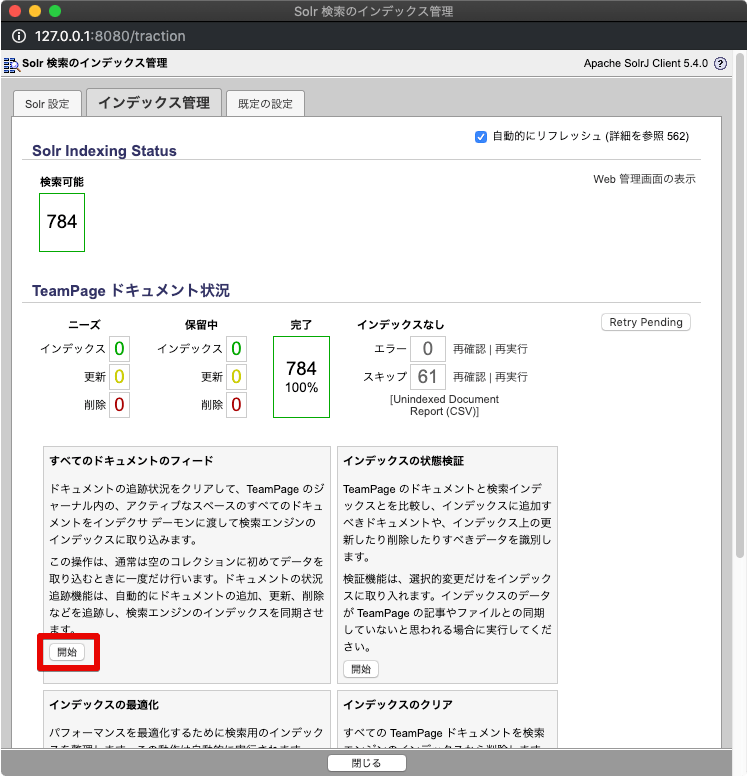
「Solr 検索のインデックス管理」画面の [すべてのドキュメントのフィード] の [開始] ボタンをクリックします。フィードが完了するまでしばらくお待ちください。
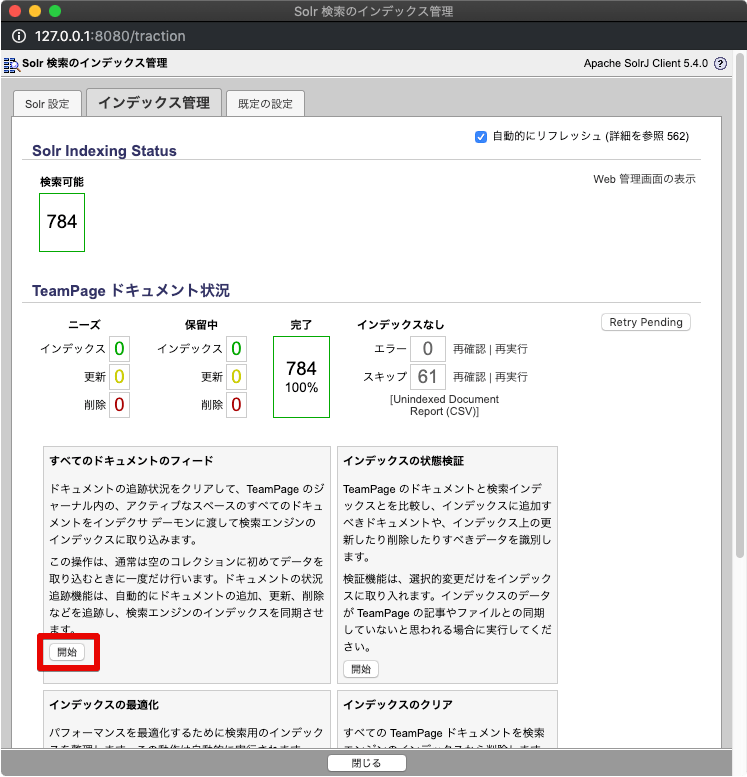
Solr を再起動します。
以上で設定変更は完了です。
動作テスト
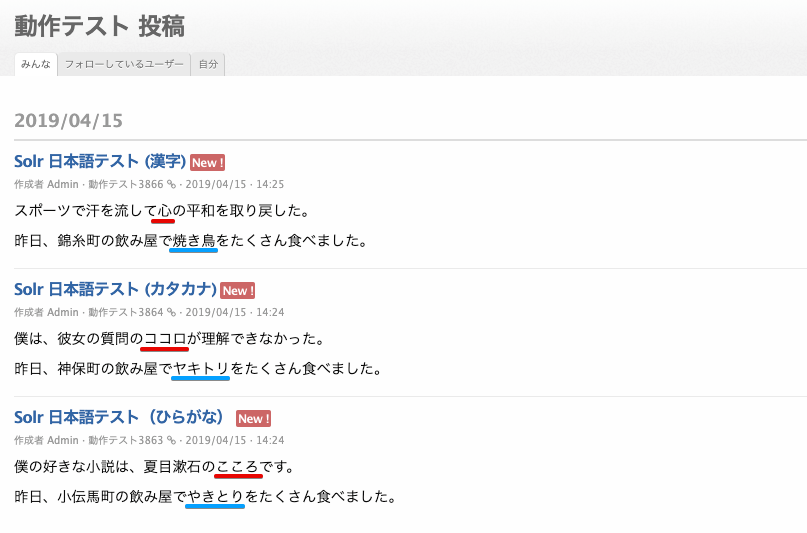
ここでは、 「心・ココロ・こころ」と「焼き鳥・ヤキトリ・やきとり」で検索テストを行うため、次の 3 件の記事を投稿しました。
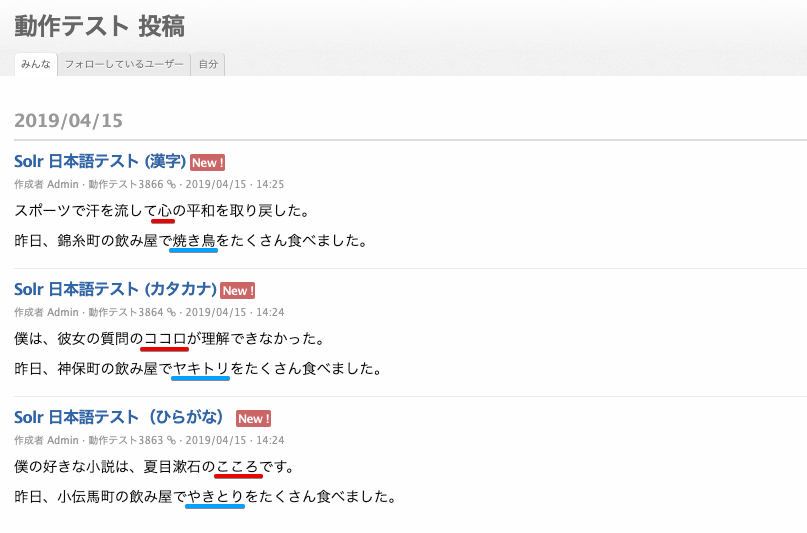
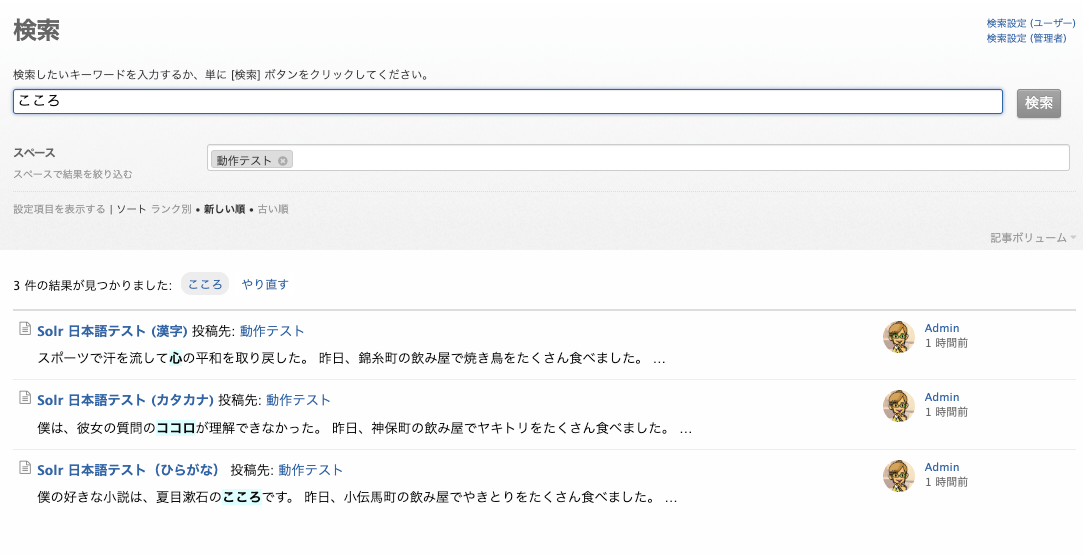
心・ココロ・こころ
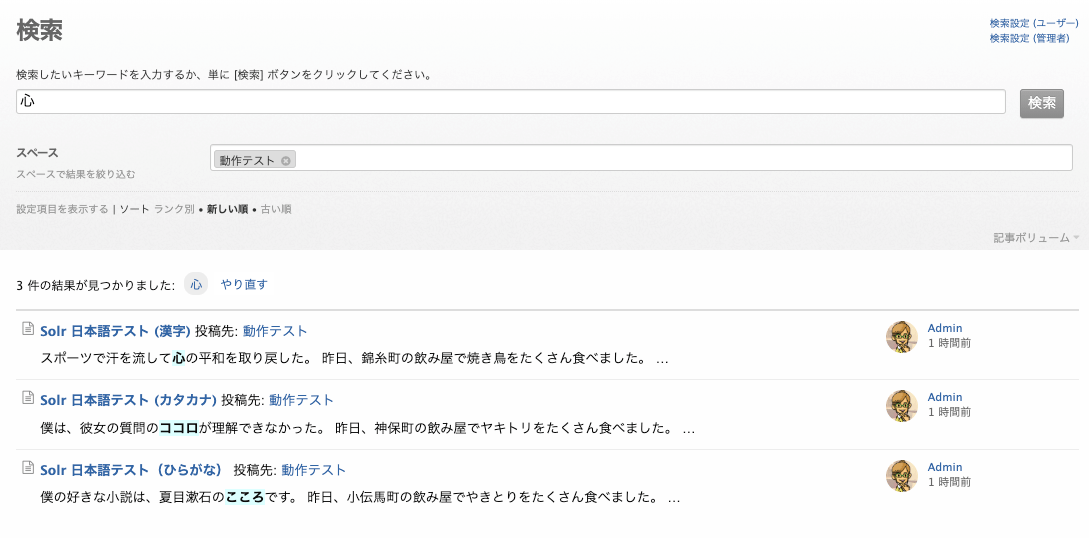
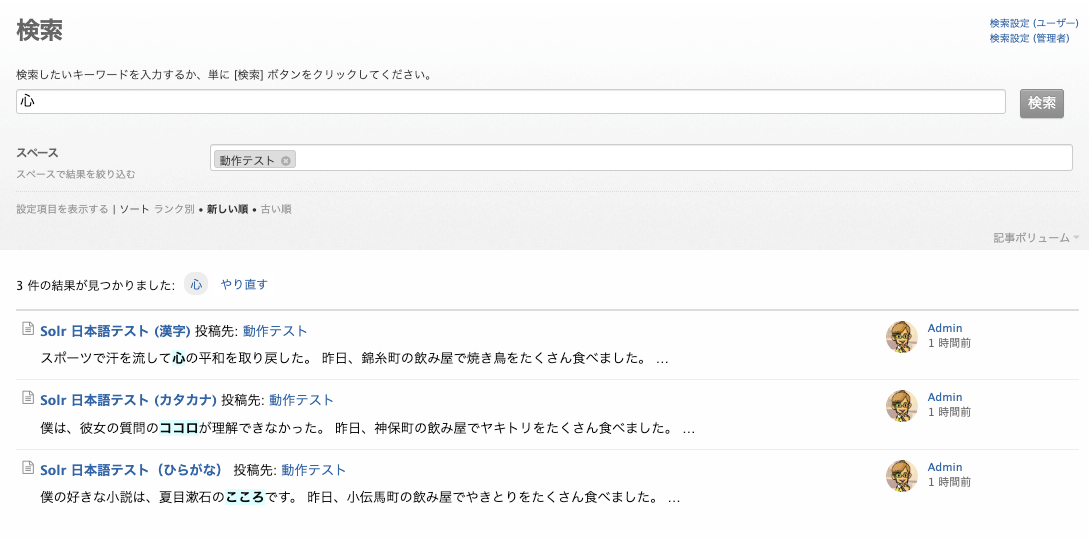
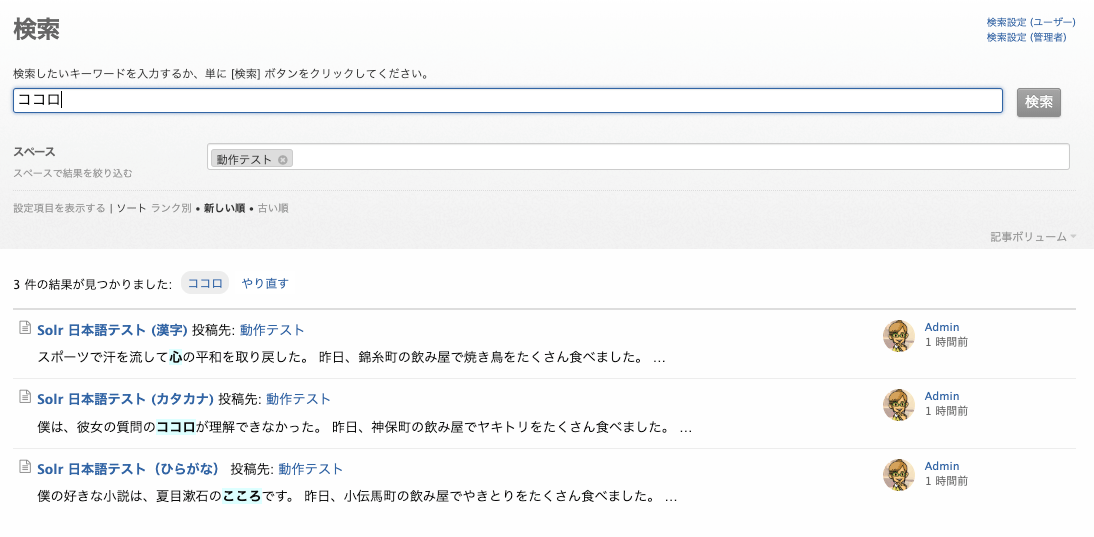
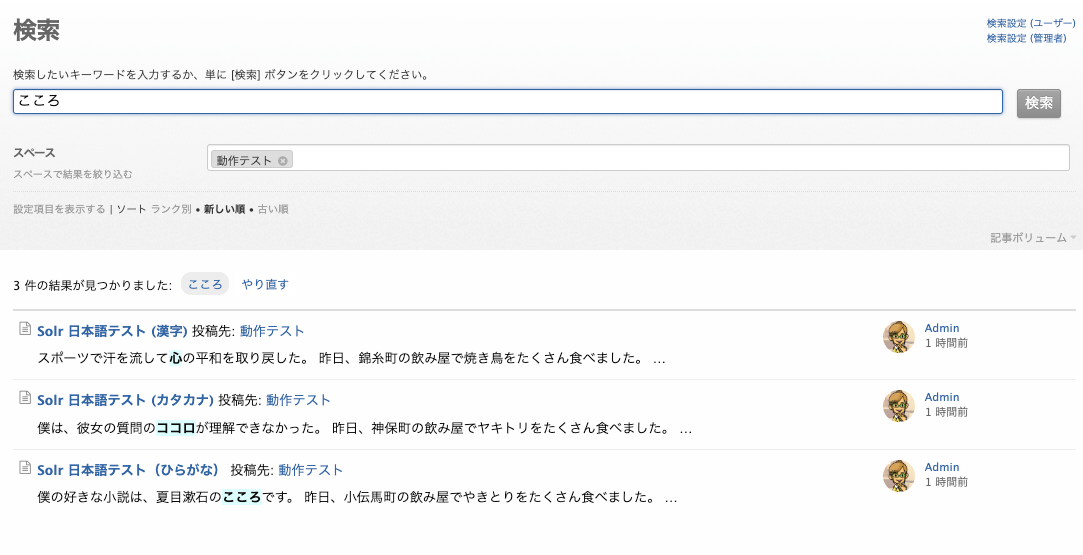
下図のように、「心」「ココロ」「こころ」のどのキーワードで検索しても、3 件の記事すべてがヒットします。
漢字の「心」で検索
カタカナの「ココロ」で検索
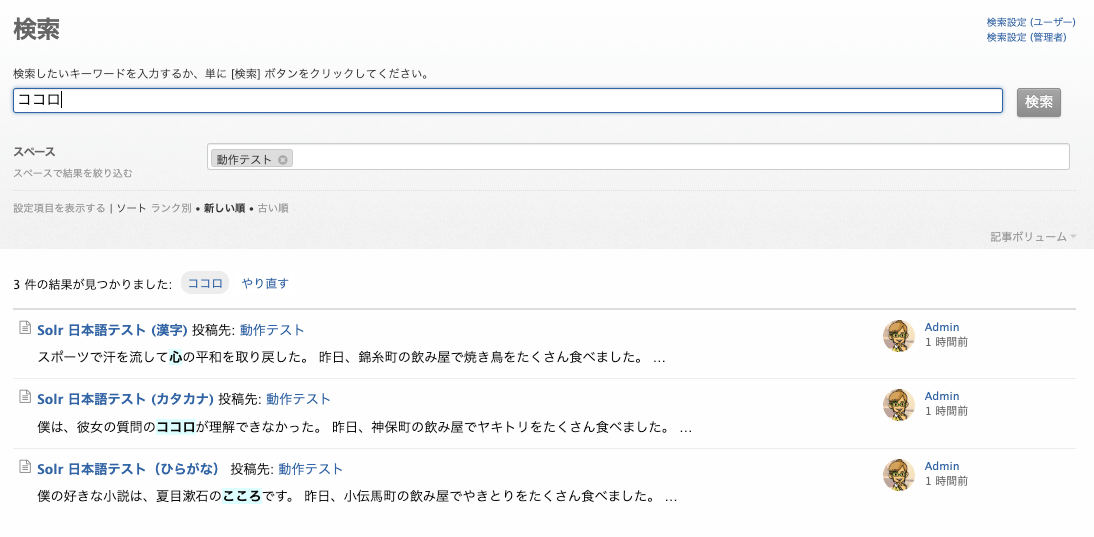
ひらがなの「こころ」で検索
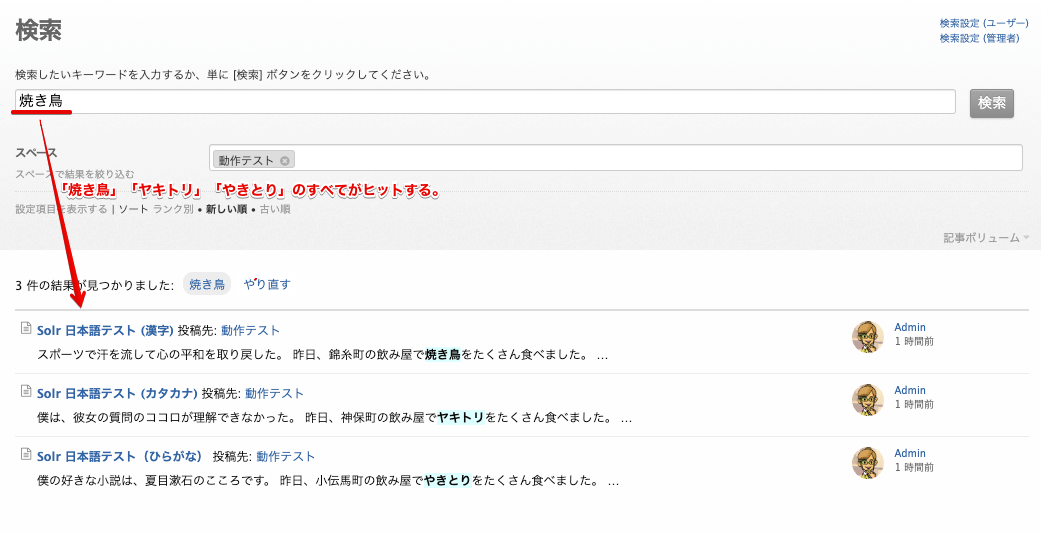
焼き鳥・ヤキトリ・やきとり
上記のように、「こころ」の検索はうまく行きましたが、「やきとり」の場合は辞書への単語登録が必要になります。
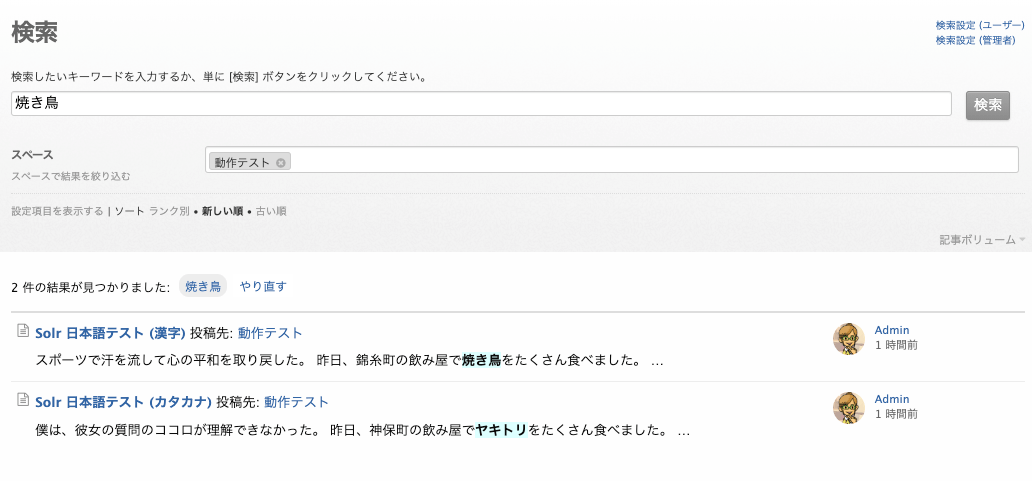
まずは検索テストの結果をみてみましょう。
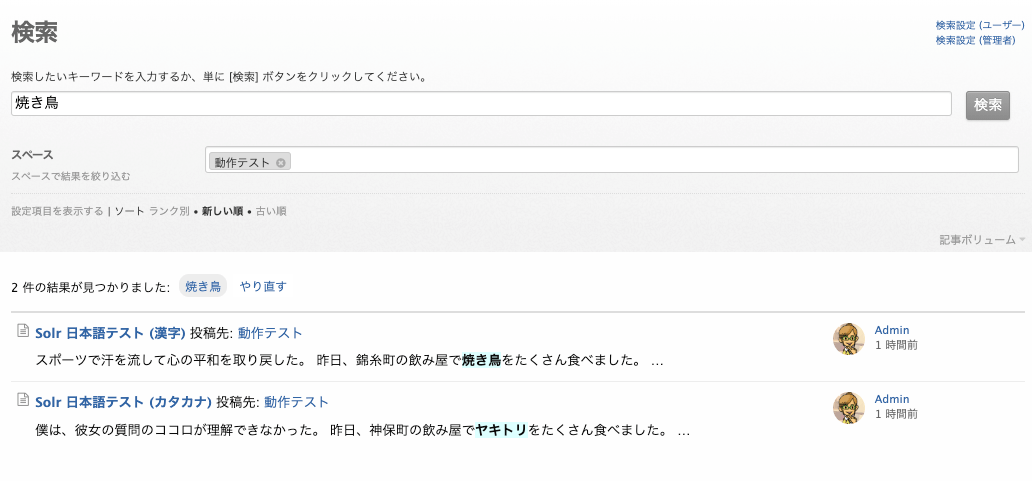
漢字の「焼き鳥」で検索すると、ひらがなの「やきとり」がヒットしません。
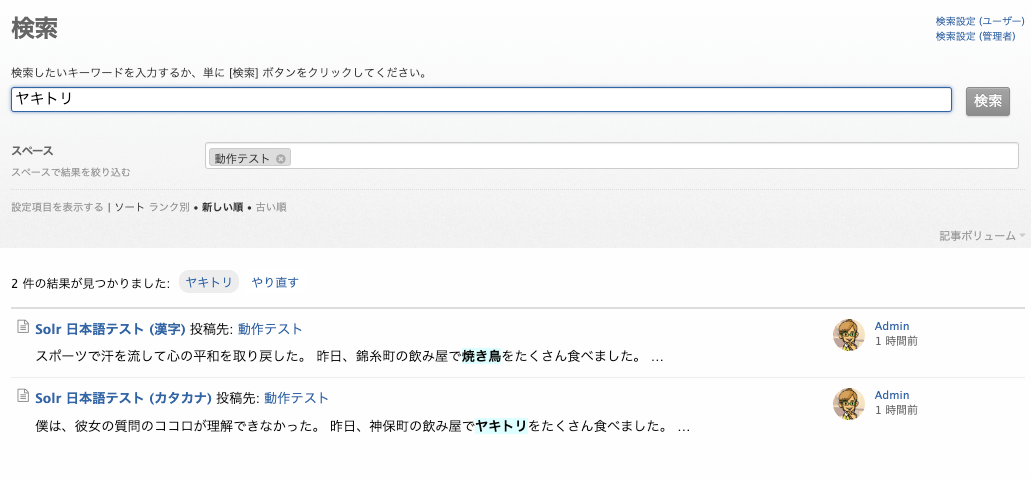
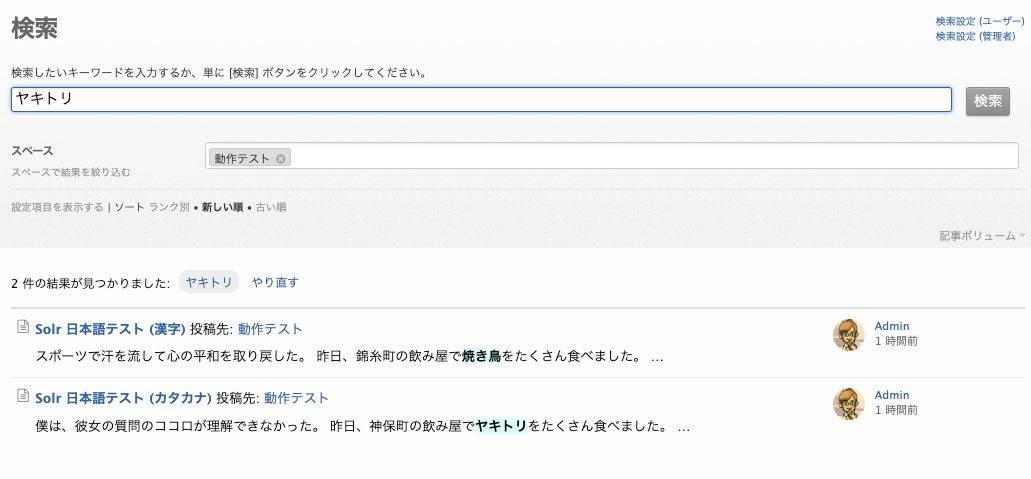
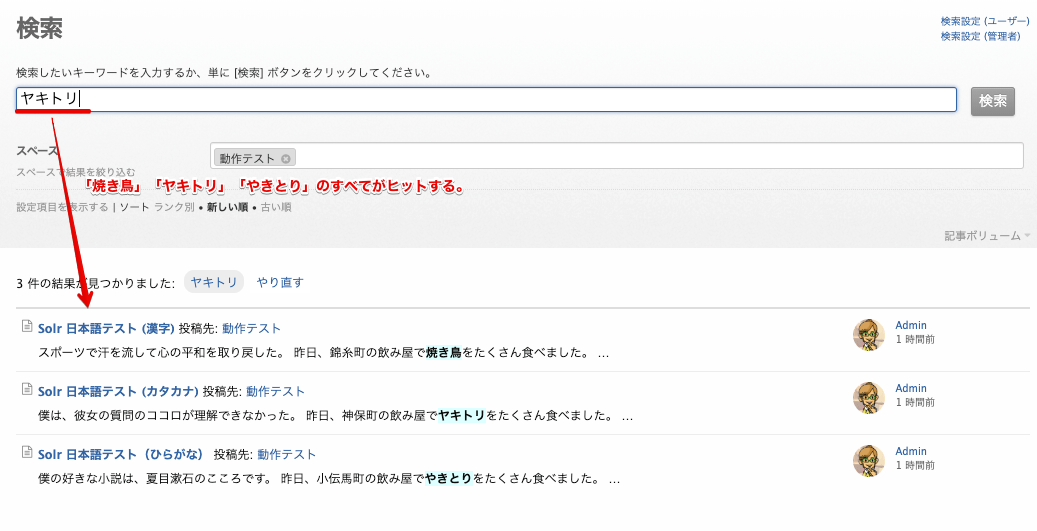
カタカナの「ヤキトリ」で検索しても、ひらがなの「やきとり」がヒットしません。
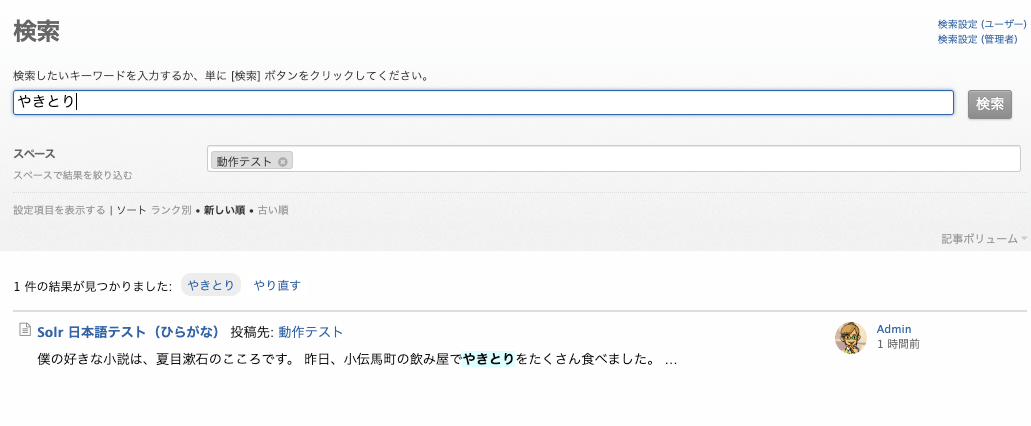
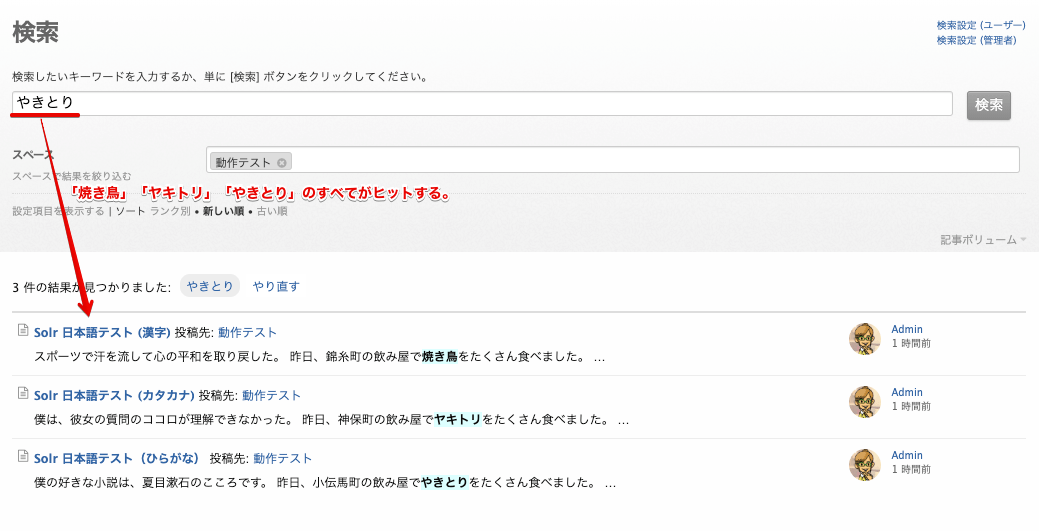
ひらがなの「やきとり」で検索すると、漢字の「焼き鳥」とカタカナの「ヤキトリ」がヒットしません。
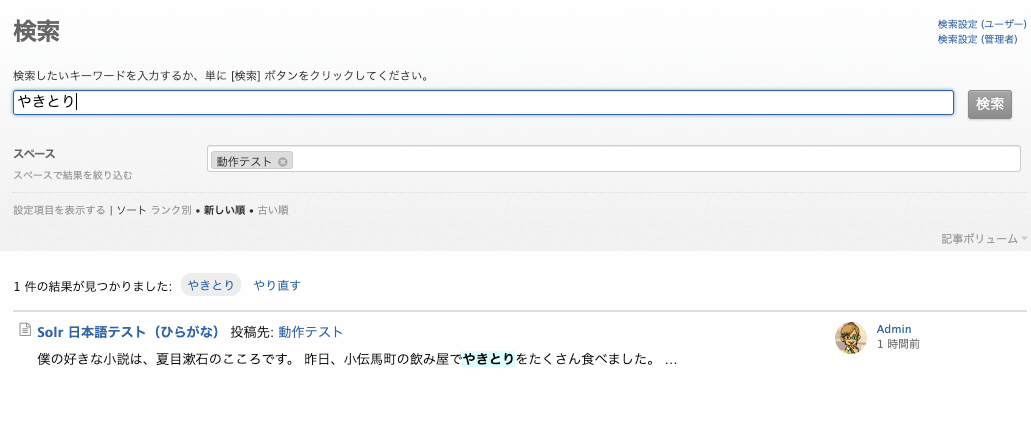
この原因は、ひらがな表記の「やきとり」が、日本語解析エンジンの「kuromoji」によって「やき」と「とり」に分割されてしまうことにあります。
この問題を解決するには、「やきとり」という単語を Solr の辞書 (userdict_ja.txt) に登録 します。
やきとり,やきとり,ヤキトリ,名詞
日本語用設定「traction_ja」を zkcli スクリプトで再インストールし、Solr を再起動します。(上述参照)
TeamPage の「Solr 検索のインデックス管理」画面の [すべてのドキュメントのフィード] の [開始] ボタンをクリックし、再フォードが完了するまで待ちます。
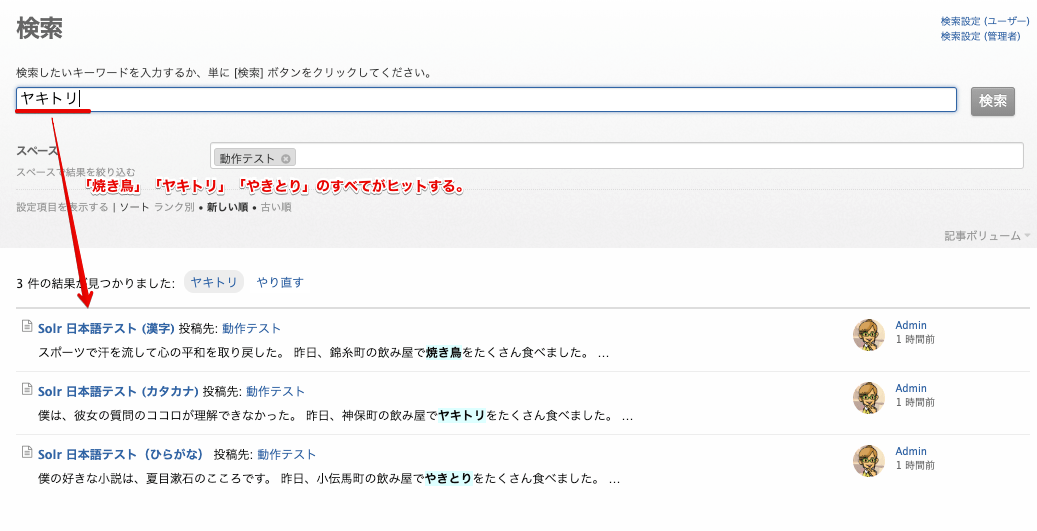
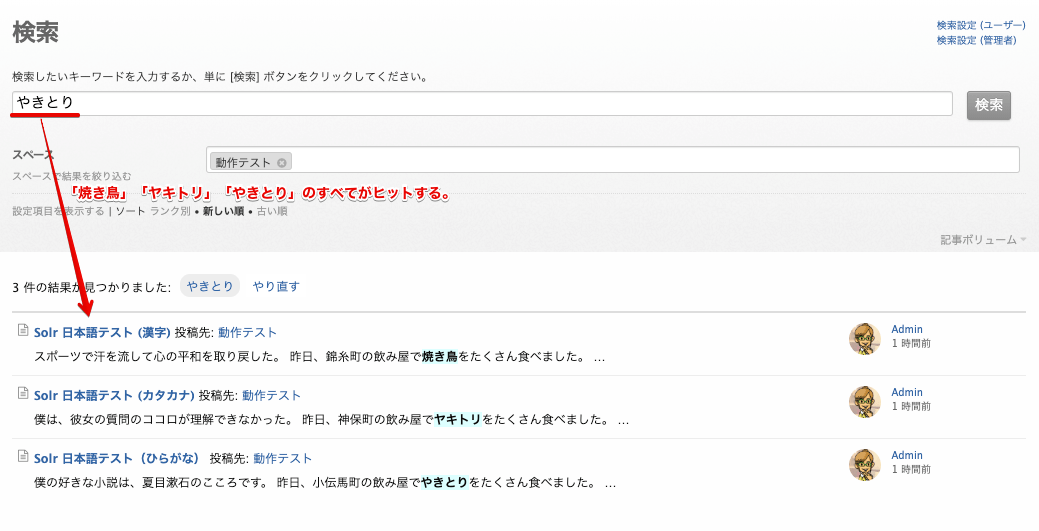
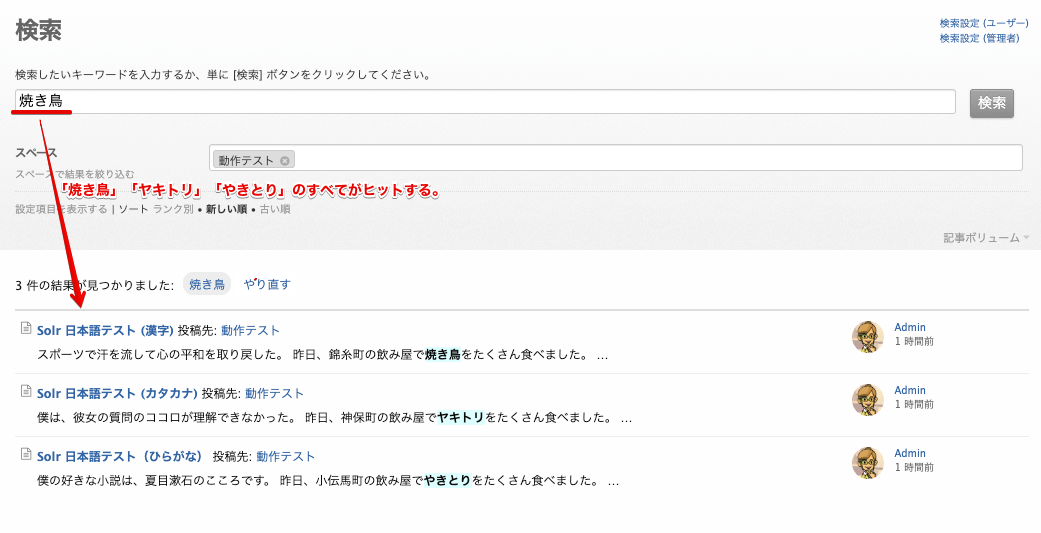
漢字の「焼き鳥」、カタカナの「ヤキトリ」、ひらがなの「やきとり」を検索してすべての記事がヒットすることを確認します。
漢字の「焼き鳥」で検索
カタカナの「ヤキトリ」で検索
ひらがなの「やきとり」で検索
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}